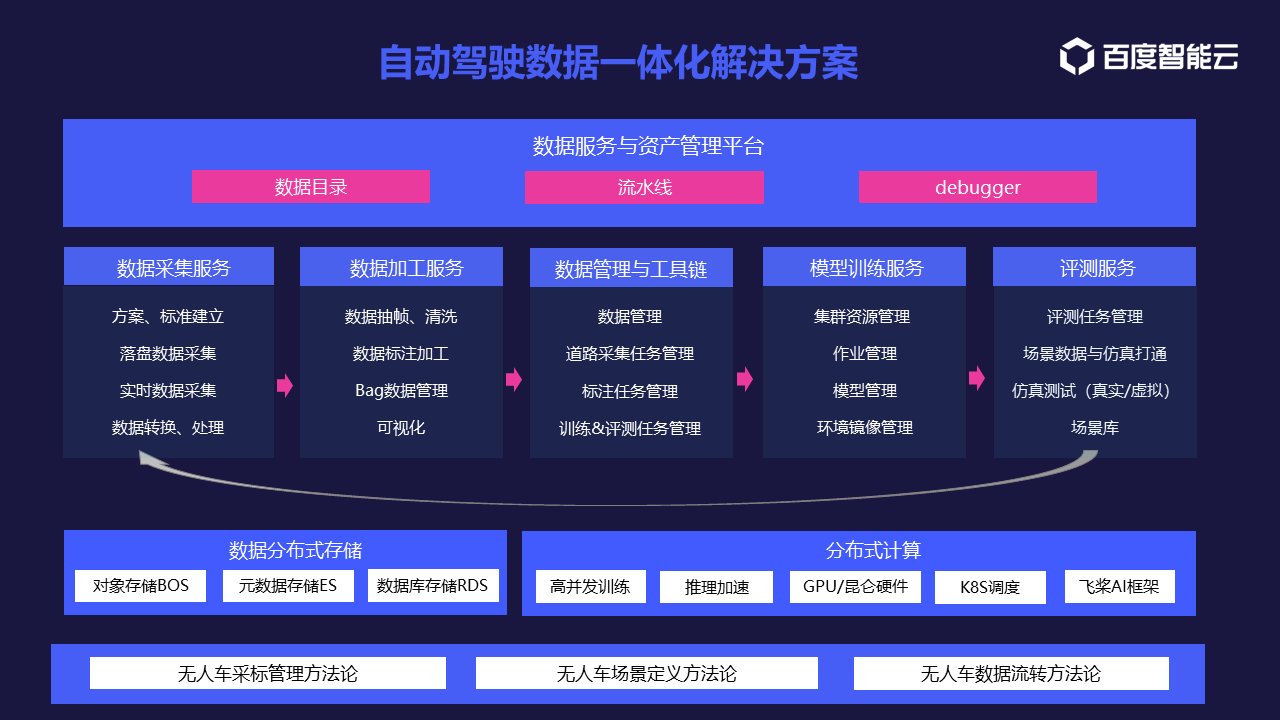
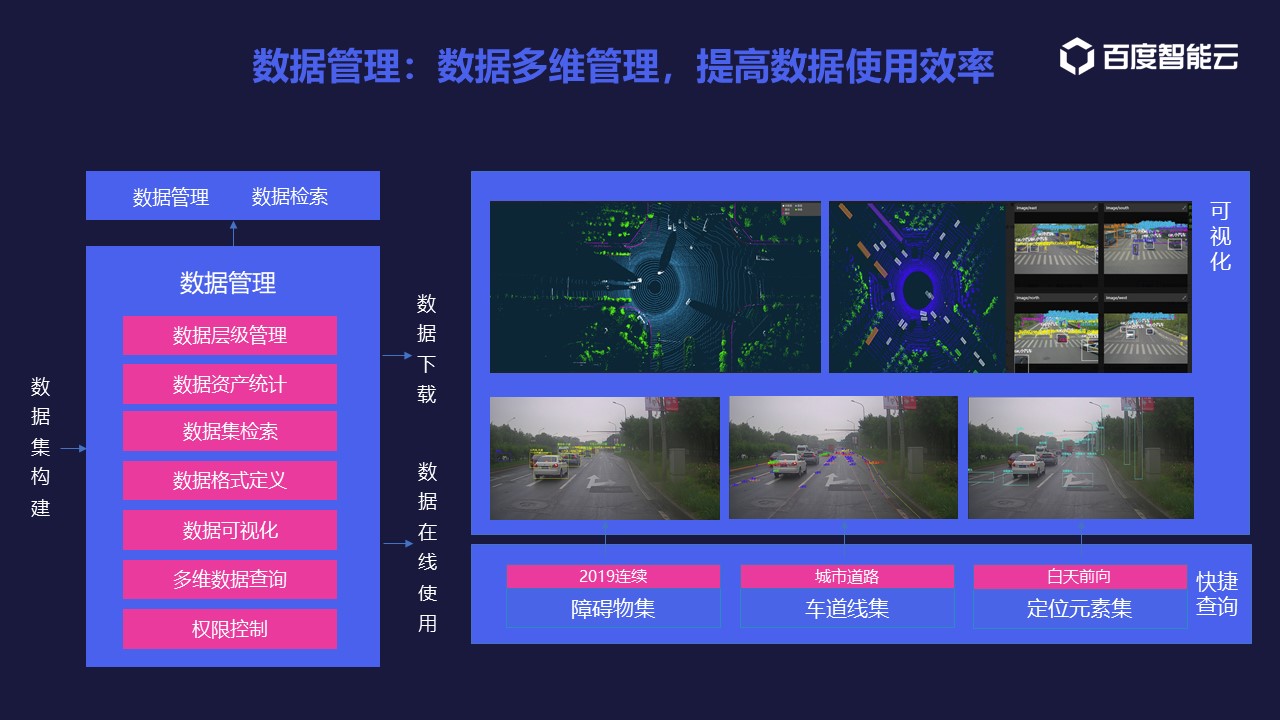
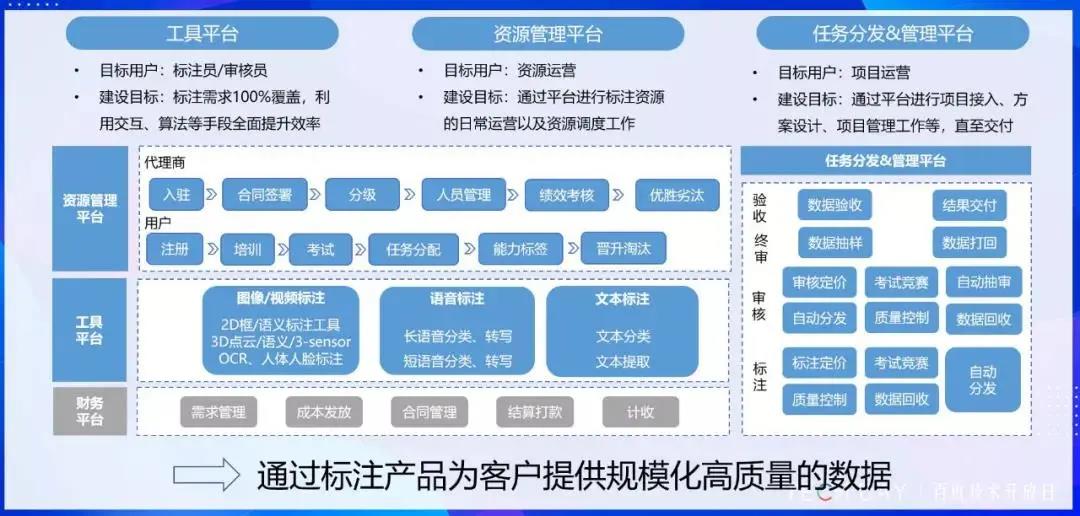
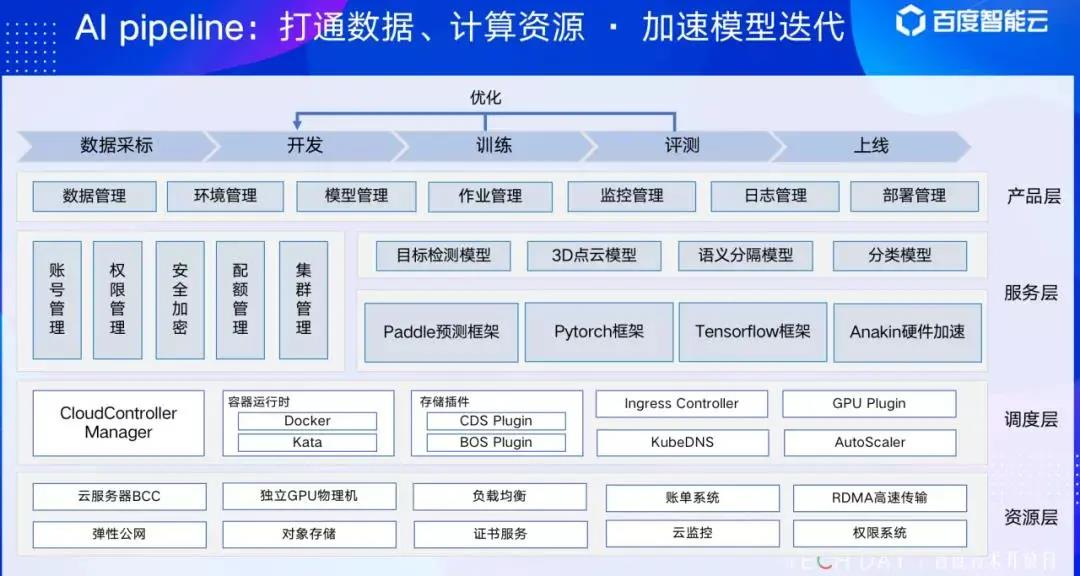
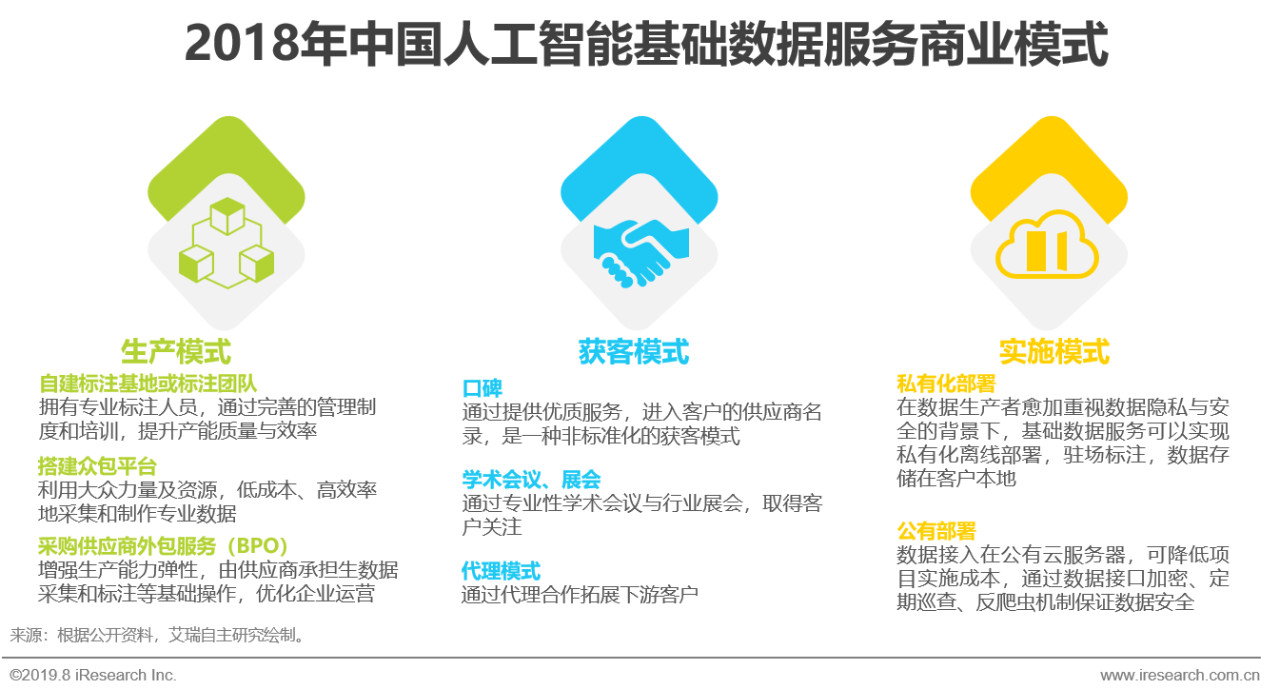
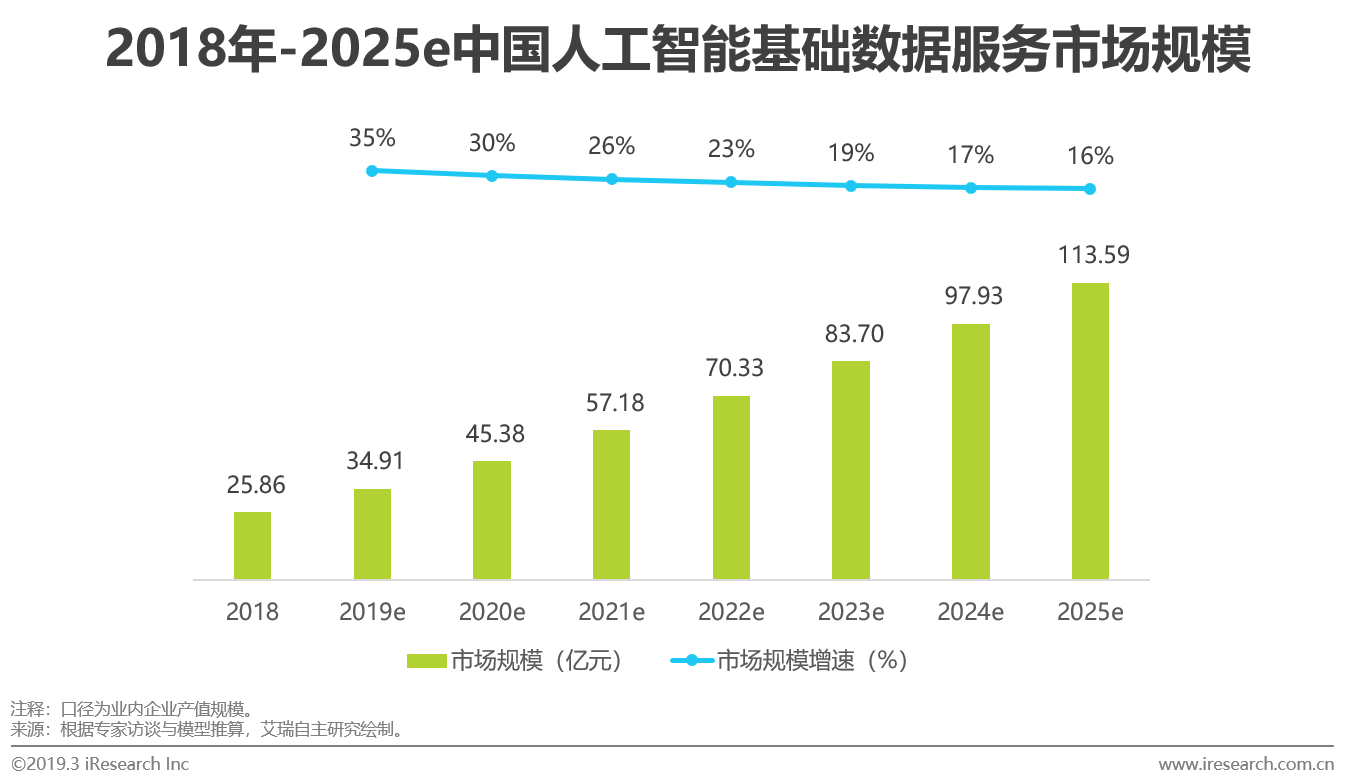
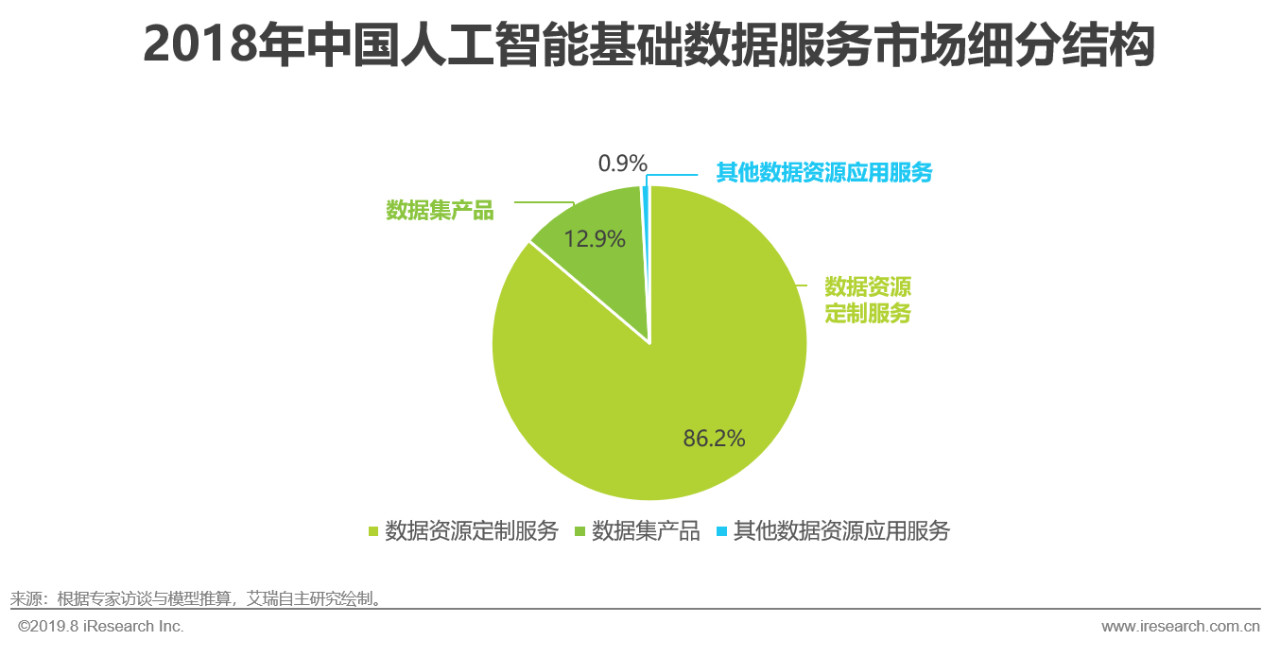
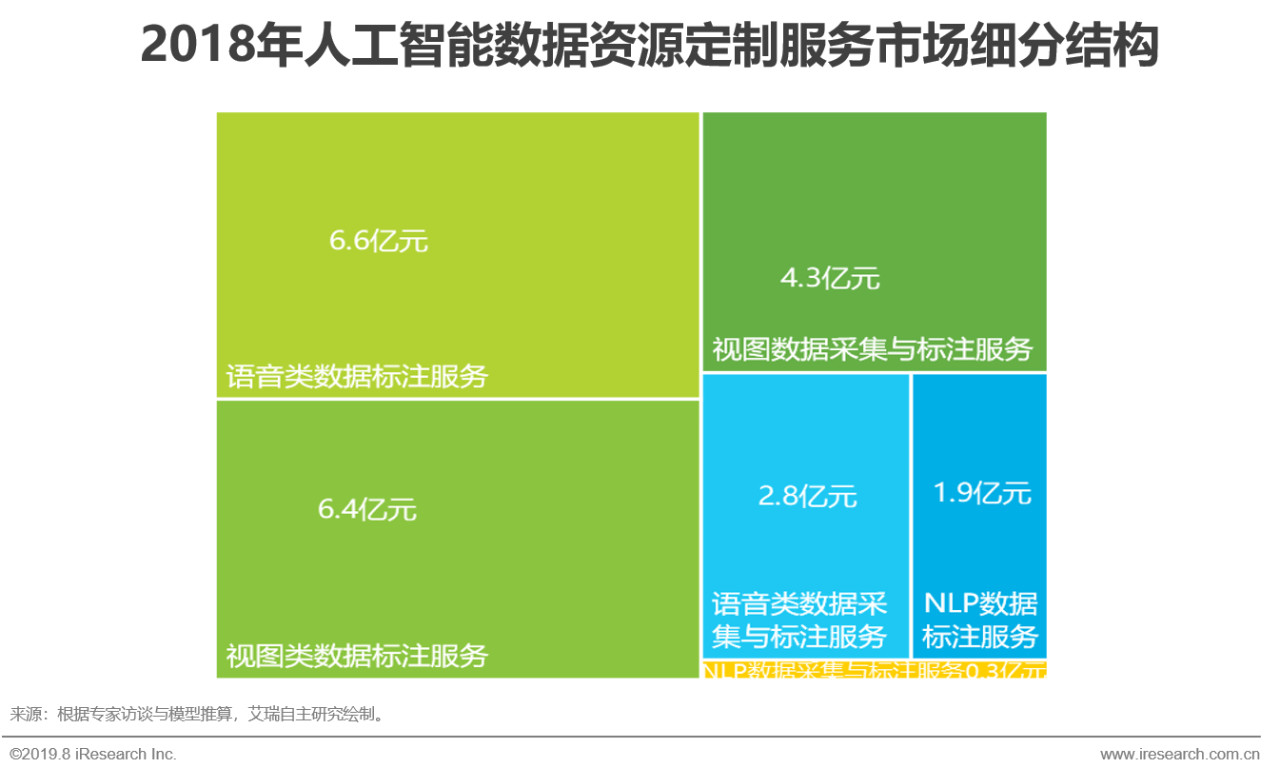
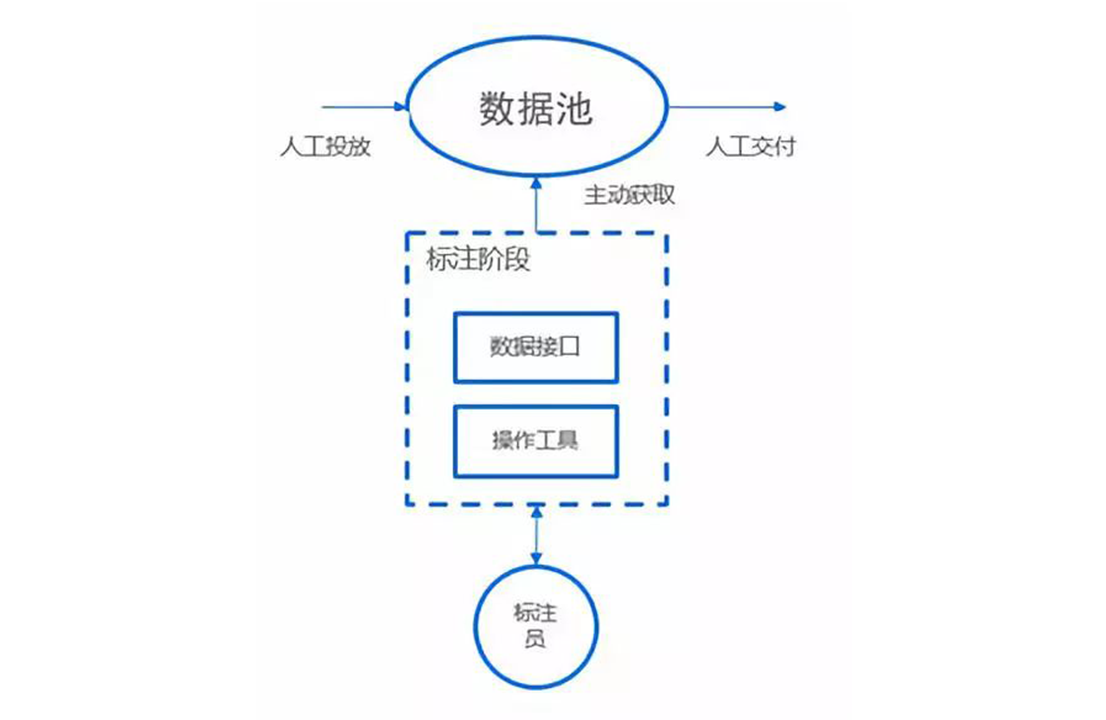
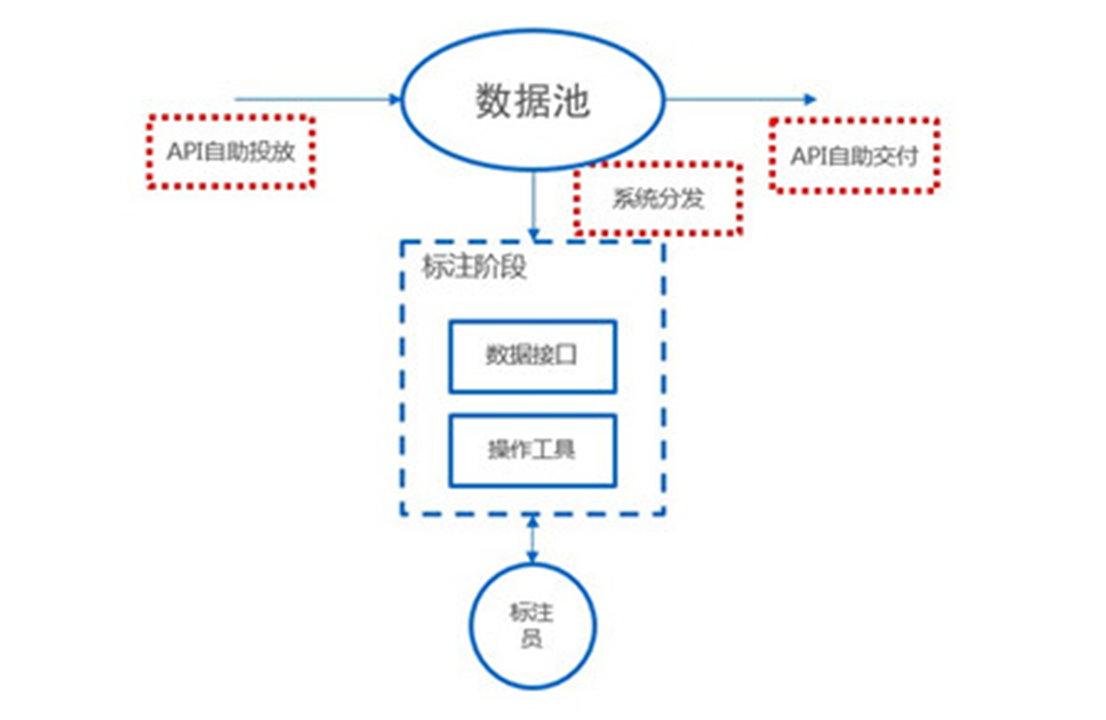
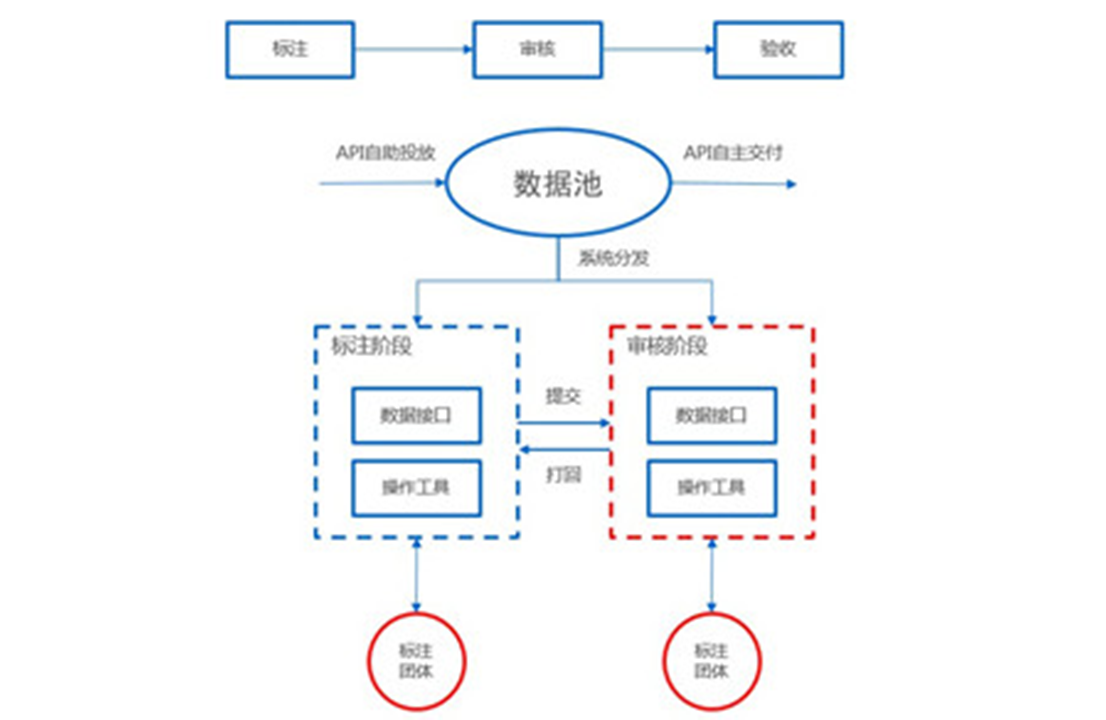
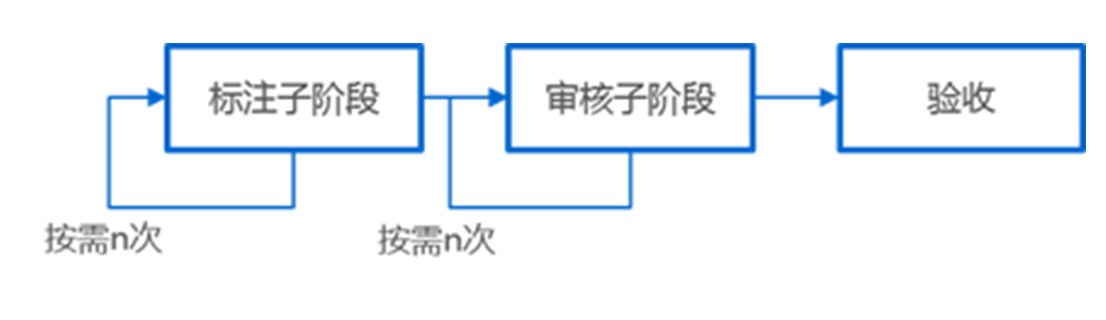
综述
百度众测(http://zhongbao.baidu.com/)作为全国最大的AI数据标注平台,自2011年成立,至今已有8个年头。随着业务的不断发展和壮大,整个站点架构也发生了翻天覆地的变化。本文基于这些年的一些经验和积累,详细描述一下属于众测的架构变迁史。
只有不断的总结,才能找到前进的道路。本文脚踏实地,回首历史长河,仰望星空。
阶段1 基于单点的网站架构
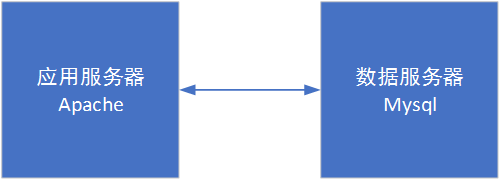
一般网站初期,常见的都是单机把所有的应用和数据库都囊括了。这种环境配置说实话有条件的话是绝不推荐的,当然有时候我们机器比较拮据的情况下也出现过应用和数据库同机部署的情况,那么代价是什么呢?
那就是难免会出现宕机的命运!
应用常见的情况都需要执行脚本,而一些脚本有可能出现内存泄露亦或是大内存占用的情况,数据库本身就是内存占用大户,一旦机器的内存过载,linux就会很聪明的kill掉数据库,让你不知所措。
因此考虑到机器容灾,建议至少把数据库和应用进行分开部署。
至于部署的话,之前已经提过经典的LAMP方式就ok。众测建站早期容器化docker并不是非常成熟,因此搭建机器都是通过脚本的方式进行。现在毫无疑问docker搭建就很方便快捷,也利于管理,也不太容易出现由于系统版本问题造成的编译调试崩溃问题。不过建议有条件还是重头装一下所使用的web各个组件,简单了解下各种编译配置的效果,以备不时之需。
目前整体的架构可以如图所示:
阶段2 数据库读写分离
能跑起来的应用是好应用,但机器难免出问题,为此数据库本身的容灾尤为重要。
本身随着业务发展,数据库难免出现因为错误代码或是误操作而导致的数据错误,甚至是物理机宕机等问题。因此数据库的灾备算是重中之重。
Mysql自带的mysqldump可以非常简单的导出数据,供数据恢复。如果有条件还可以进一步备份binlog,以此可以达到秒级别的数据恢复。不过需要注意的是mysqldump时会出现数据库锁表,单库的话,你的服务可就再见了。
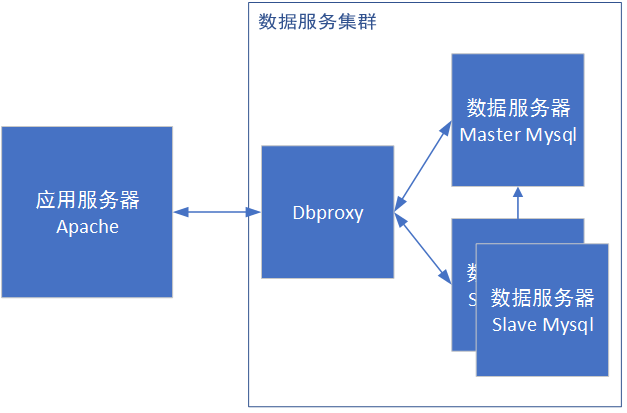
这时候就轮到mysql自带的master+slave闪亮登场了!
从库(slave)的好处都有啥?
简单总结就两点:
从库主要进行读取服务,可以极大减少主库的服务压力。
专门部署的备份从库,可以放心地进行数据的备份。
不过引入slave后,烦躁的问题也有不少:
首先,需要对数据库前架设一个读写代理服务。我们使用了厂内自研的dbproxy组件,使用时完全感知不到其存在。开源的话可以使用mycat,甚至一些框架已经支持配置主从。
其次,主从引入后,主从不一致必然成为业务代码中需要考虑的一个问题。一般常见的错误场景是写入主库后,直接读取该条数据,由于主从瞬间的不一致,会出现读取不到case。当然,建议尽量减少业务代码如此实现,但是一些特殊场景下可能避免不了。建议使用对操作加事务或是强制访问主库连接的方式来处理这一case。
加上了从库,感觉越来越稳定了呢:
阶段3 负载均衡+多应用服务器
随着访问量继续增加,单台服务器基本无法满足需求了。一般会选择增加机器的方式用钱来换稳定性。但是加机器不能简单说说就加上了,会碰到以下这些问题:
1、第一个问题用什么技术做负载均衡:
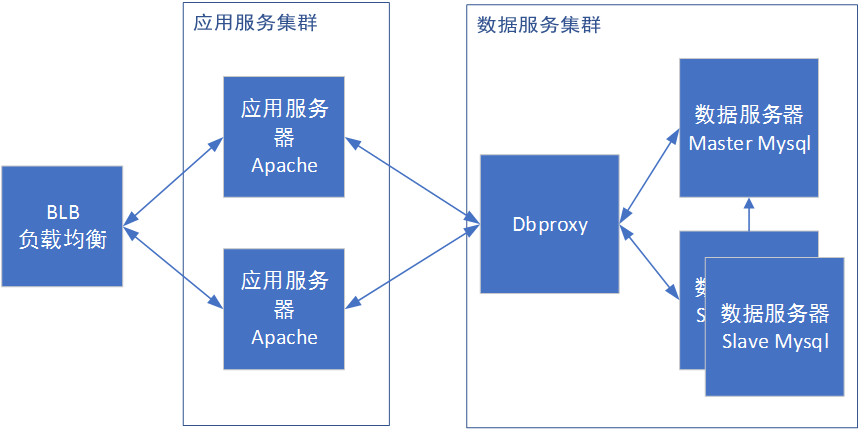
首选是使用反向代理服务器。请求由反向代理服务器根据算法转发到具体的服务器,常见的apache和nginx都可以配置转发规则到其他机器上。部署相当简单,但是代理服务器可能成为性能的瓶颈,同时也有单点问题。
另一种更加底层的方案是使用IP层负载均衡。在请求到达负载均衡器后,负载均衡器通过修改请求的目的IP地址,从而实现请求的转发,做到负载均衡。整体比反向代理性能更好,但是也存在单点问题。
当然更复杂的情况下会选择DNS等方式做负载均衡,不多做展开。
2、第二个问题是选择集群调度算法。
首先,最常见的rr 轮询调度算法和wrr 加权调度算法,简单实用。
其次,使用散列方式的进行转发。常用用户ip等信息作为散列值,保证用户每次访问到的都是同一台服务器。
最后基于连接数进行数据分发。比较基础的有lc 最少连接,即连接请求较少的服务器。wlc 加权最少连接,在lc的基础上,为每台服务器加上权值。算法为:(活动连接数*256+非活动连接数)÷权重 ,计算出来的值小的服务器优先被选择。
当然还有更多更复杂的算法可以应用,这里不再多做介绍。
3、最后有别于单台服务器,session的共享是需要考虑的。
一般框架都提供了基于redis或是数据库的session共享配置,简单配置即可使用。不过需要注意的是在访问量较大的情况下,单redis和单库存在连接数打满的风险,需要进行进一步的扩容。
我们实际使用中,一般直接使用开放云架构的BLB。其提供http层和tcp层两类负载均衡的方式,可使用wrr方式进行负载均衡。同时,具备心跳检测,有效剔除了失效服务。
到目前为止,一个集群已经初具规模:
阶段4 数据库拆分
进行到本阶段,很有可能出现的问题有两个:单库维护了上百张表,维护起来十分头大;单表的数据已经达到了千万级别,查询出现性能问题。针对这两种情况,就需要引入水平拆分和垂直拆分:
垂直拆分的意思是把数据库中不同的业务数据拆分到不同的数据库中,例如我们会拆分标注、问卷等不同的场景,将数据库分开放,也因此可以避免单库性能拖垮全站的情况。
带来的新问题是如何处理跨库事务,目前我们一般使用代码控制,一些重要逻辑在每个库都支持自己独立的回滚。
数据水平拆分就是把同一个表中的数据拆分到两个甚至多个数据库中。一般用于解决单表过大的性能问题,同时方便扩容。
不过如何拆分是一个需要好好设计的点,目前如mycat模块可以根据配置对sql进行转发到库的操作,以此达到拆库的目标。
而在我们业务初期,这些组件还刚刚起步。我们最初使用的简单按月拆库的设计方案。简单来讲就是按照任务的发布月份,放到不同的月份库。按照过期时间,将冷数据灌入只读数据库来压缩存储容量。
不过随着业务量指数级别上升,单库的容量逐渐失控,我们进一步调整了分库的策略。目前我们自行设计了一个更细粒度的分库策略,基于任务-数据库映射表来实现,在任务创建初期有分库算法分配对应数据库,之后任务的生命周期中都会基于被分配的数据库进行CURD。
有了分库分表之后,我们的业务框架呈现如下:
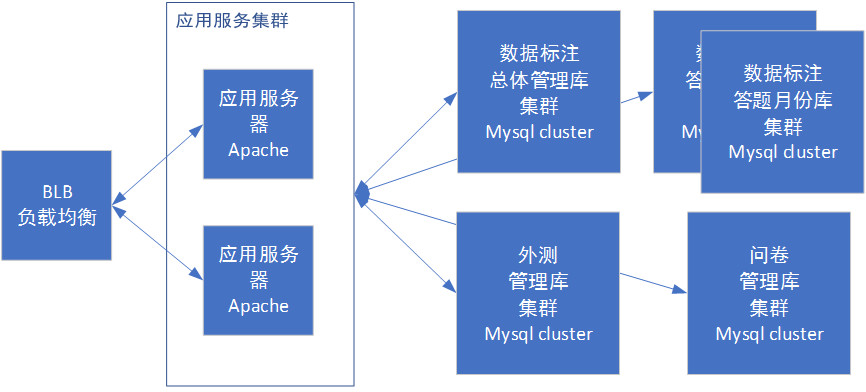
阶段5 应用和模块拆分
上阶段我们已经将数据库进行了拆分,而实际上业务代码的拆分也应该随着数据库的拆分同时进行。
和数据库类似,我们按照业务模块拆分了包括问卷和标注在内的多个模块。本身业务代码是各不相同的,这种拆分比较顺理成章,但是比较痛苦的是业务代码会需要很多公用的逻辑,例如一些通用的string和array处理。一种建议是将这些通用逻辑放到framework的component里,以此来达到公用的目的。
另外此阶段可能一些公共服务模块(如用户信息)在理想情况是需要独立部署维护的。不过作为一个过渡阶段,考虑到开发的工作量,我们将公共模块在部署时拷贝至各个集群,后续阶段再计划进行独立拆分。
业务拆分后,我们的拥有了多个子系统:
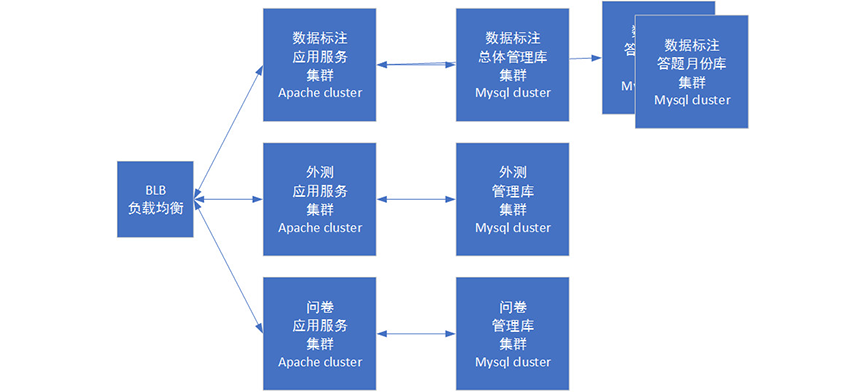
阶段6 数据缓存
随着系统的不断复杂,渐渐会发现使用mysql处理很多应用场景有比较大的困难,如以下几种case:
用户时常会提交一些验证码等信息,如果都用数据库存储这些短效大量数据,似乎杀鸡用了牛刀;
一些复杂的分页信息很难用数据库直接计算,需要内存中组合数据进行计算。但是对于这种case,换页操作也不可避免,因此需要大量在内存中频繁读取数据库的值。
以上这些问题,引入缓存nosql解决起来会舒服很多,目前比较常用的就是redis了。
验证码信息可以使用key-value的方式直接存入redis,设定key的过期时间来避免redis存储过多的冷数据。
而复杂的分页信息,可以把页id信息存储到redis中。能够在换页时直接拿取redis中的分页信息,不必再进一步计算。
Redis还可以用来做一些消息队列、session存储以及数据缓存的功能,是必不可少的一层数据存储方案。
引入redis后,模块大致如下:
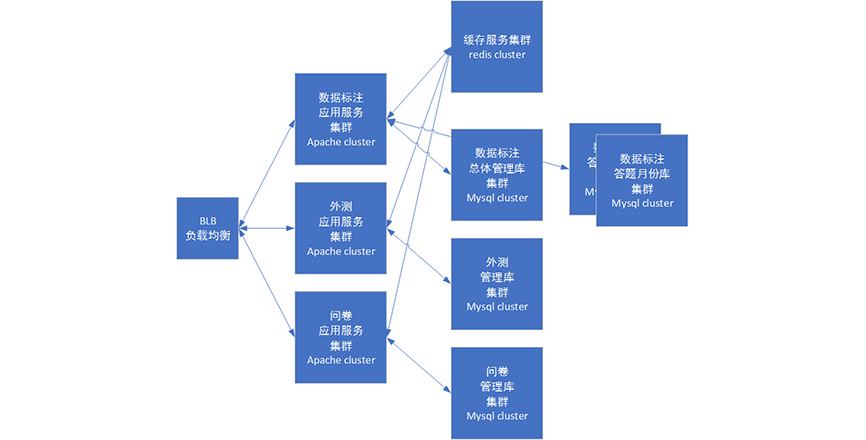
阶段7 微服务化
随着业务拆分的进行,会发现模块的组织切分尤为高深,这也是目前我们正在面对和解决的阶段。常见的一种设计思路是微服务架构:系统中,每个服务都有自己的处理和轻量通讯机制,能部署在单台或多台机器上,达到快速扩容。
一个优秀的微服务系统会具备如下几个特性:
如何搭建微服务系统并不是简单几句可以说清的,有需要请另行深入阅读学习。我们目前推行的微服务架构简图如下:
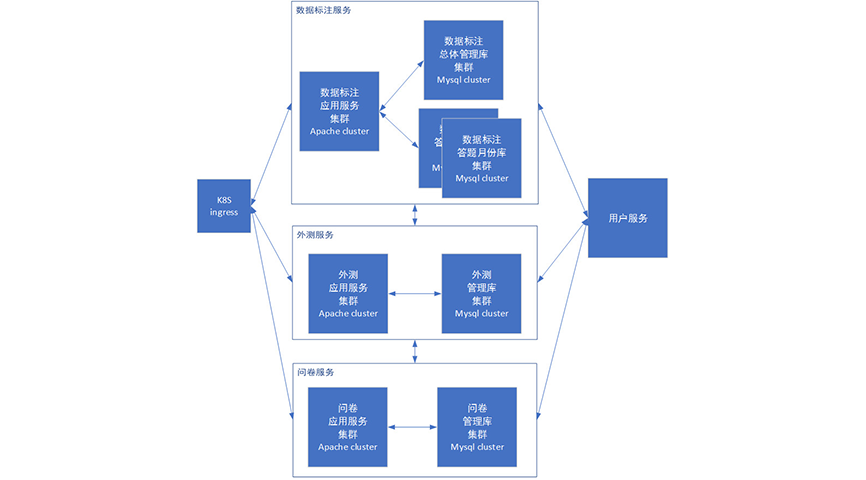
和上一阶段看上去非常接近,不过其实主要区别是:上一阶段中各个集群中实际都会部署全量的代码,只是通过区分路由方式来保证请求进入到不同集群。例如外测服务需要调用标注服务的功能,只需要直接调用其代码即可工作。
而在微服务阶段,各个服务本身的代码尽量精简,几乎不会相互交叉。相互之间的调用需要使用接口的方式进行通讯。
总结
网站架构是一直长期发展的,如今先进的技术早晚也难免被过时淘汰。所以在搭建架构的时候脚踏实地,搞懂每一个设计的前因后果,才能夯实基础,仰望星空。
切忌不可以为了先进的架构而跃进式地升级,如果没有想清楚如何拆分、如何设计,只凭一股勇气,只会撞得头破血流折戟沉沙。
参考:
《浅谈web网站架构演变过程》:
https://www.cnblogs.com/xiaoMzjm/p/5223799.html
《大型网站技术架构:核心原理与案例分析》——李智慧著
《mycat权威指南》